本节内容是《C++并发编程实践》5.3节的笔记
在C++内存模型中, 内存序(memory order) 定义了多线程环境下原子操作的可见性与执行顺序约束。它直接影响指令重排、CPU缓存一致性以及跨线程数据同步效果。
首先我们需要引入两种内存模型关系:“先行(happens-before)”和“同步(synchronizes-with)”
在原书中,这些内容比较晦涩难懂,下面的总结也并不完全符合原意
先行(HB)
先行可以理解为:如果 A happens-before B,那么A 中的所有副作用(写入、读到的值、释放资源等)在“语言内存模型”意义上都必须对 B 可见,并且 B 不能在模型上“跑到 A 前面去”。
可以简单理解为:“这段写入对另外一段读取一定可见”
同步(SW)
同步是更加底层,更加具体的关系:
它描述的是:某个线程里的一个同步操作(通常是 release)与另一个线程里的某个对应同步操作(通常是 acquire)之间建立的跨线程连接。
一些同步来源:
mutex的unlock()与随后成功获得同一把锁的lock()之间condition_variable的notify/wait配合(严格规则更细,但本质也是建立 SW,从而得到 HB)atomic_thread_fence(栅栏)在特定搭配下也能形成 SW
可以把 SW 当成“跨线程打通的一根线”:只有打通了这根线,HB 才能跨线程成立
原子操作的内存次序
C++标准库提供了6种内存次序,但是只代表3种模式:先后一致次序(memory_order_seq_cst)、获取-释放次序(memory_order_consume、memory_order_acquire、memory_order_release 和 memory_order_acq_rel)、宽松次序(memory_order_relaxed)
memory_order_seq_cst
memory_order_seq_cst是最严格的内存次序,属于先后一致顺序,所有seq_cst的原子操作之间都有一个全局单一中顺序。这个顺序是最直观,最符合自觉的内存次序, 但由于它要求在所有线程间进行全局同步,因此也是代价最高的内存次序。在多处理器系统中,处理器之间也许为此而需要频繁通信。
例如下面代码:
1 |
|
断言一定不会被触发,也就是说z一定不会等于0。因为对x和y的写入操作一定会先行发生,虽然不确定到底是先写x还是先写y。如果read_x_then_y中的y载入失败返回是0,那么上面x的载入一定不会是0,也就是说,x的存储操作一定发生在y载入之前。这种情况下,read_y_then_x一定会执行到++z。因为前面保证了x比y先写入,这个函数里已经等到y存储成功了,那么x也是一样的。函数上面的while保证了y在这里为ture,按照memory_order_seq_cst次序,所有以它为标记的原子操作都会形成**单一的全局总操作序列**。
根据对称性,事件也有可能会以相反的方式发生,也有可能x、y在read_*之前都已经被存储了,那么z会等于2.
memory_order_relaxed
memory_order_relaxed属于非先后一致顺序,宽松次序。在宽松次序下,原子类型上的操作基本不存在同步关系。在单一线程下,同一个变量上的操作仍然服从先行关系,但是没有对线程间的次序做任何要求。
- 只保证原子性(在同一个线程里面不会撕裂),以及该原子对象自身的“修改顺序(modification order)”
- 不提供跨线程的可见性/排序保证
- 适用:计数器、统计、ID 生成、无须发布数据的场景
对于这个内存序,书中有一个很好的例子,值得研读一下。这里只是简单总结
给一段例子:
1 |
|
这段代码输出的结果不唯一
1 | (0,0,0),(1,1,0),(2,2,0),(3,3,0),(4,5,0),(5,5,0),(6,7,0),(7,8,0),(8,9,0),(9,10,0) |
请注意以上输出的几个特点:
- 第一行中考察所有三元组内的第一个值,变量x的值以1为增量逐渐递增;
- 第二行中三元组的第二个值,即变量y的值同样如此;
- 第三行中三元组的第三个值,即变量z的值也一样。
三元组中表示x的元素仅在同一行输出中递增,y和z也是,但它们的递增幅度并不稳定,分别形成的相对序列在每个线程上也都有异。 线程t3并没有看见变量x和y的任何更新,它仅仅看见自己对变量z的更新。尽管如此,这并不妨碍其他线程看见变量z的更新,它们还一并看见变量x和y的更新。
我们可以看见,对于自己线程内的操作,宽松次序确实是会形成先行关系,但是对于线程外的,只会保证不会获取到之前的值。
之前的值:假设对变量的赋值顺序是{1,2,3,4,5},宽松次序保证如果某一次获取到3,那么绝对不会获取到1、2,只会获取到4、5。同时,获取到的值并不一定是最终更新的值,只会保证不会获取到当前获取到值的更旧的值。
非必要情况下,是不太建议使用这个次序的,即使要用,也要保持十二分警惕。
memory_order_acquire和memory_order_release
这两个次序属于获取-释放次序,比宽松次序严格,并且可以实现同步的效果。
memory_order_acquire用于load上,要与memory_order_release配合使用。
- 保证:本线程中此 acquire 之后的读写,不能被重排到它之前
- 与另一个线程对同一原子变量的 release 配对时,会建立 synchronizes-with,进而导出 happens-before
- 适用:读“发布标志”、读指针/状态以“获取”别的线程发布的数据
memory_order_release用于store上,要与memory_order_acquire配合使用。
- 保证:本线程中此 release 之前的读写,不能被重排到它之后
- 与另一个线程对同一原子变量的 acquire 配对 → 建立同步
- 适用:发布数据(先写数据,再 release-store 标志/指针)
1 |
|
上面代码中,断言不会被触发。尽管thread_3只是接触了sync2,并没有接触thread_1的sync1,但是仍然通过thread_2中同时接触sync1和sync2形成了同步。
thread_2中while等待sync1写入变得可见,同时将sync2写入。在thread_3中while等待sync2写入变得可见,同步可以传递,既然sync2的写入已经变得可见,那么sync1的写入也是可见的。因为sync1的写入早于sync2。同理,sync1同线程之前的写入也是一样可见的,所以在thread_3中,xdata的写入时可见的。
其实C++中的memory_order_consume次序也是获取-释放次序的组成部分,但是C++17已经开始不建议使用,并且C++26已经将其弃用了。在代码中不建议使用,凡是要用到这个次序的,都应该改成memory_order_acquire次序。
memory_order_acq_rel
memory_order_acq_rel用在 读改写(RMW)上:fetch_add/exchange/compare_exchange...
- 同时具备:
- 对外像 release(之前不跑到后面)
- 对内像 acquire(之后不跑到前面)
- 适用:需要既“接收”又“发布”的原子更新(比如无锁结构的状态推进)
这个其实和上面的acquire和release一样,只不过是配套使用。
内存屏障(栅栏)
栅栏是原子操作程序库的一部分,通常可以和memory_order_relaxed次序的原子操作组合使用。栅栏操作全部是通过全局函数执行。 当线程运行至栅栏处时, 它便对线程中其他原子操作的次序产生作用。
下面演示了栅栏如何限制CPU执行顺序:
1 |
|
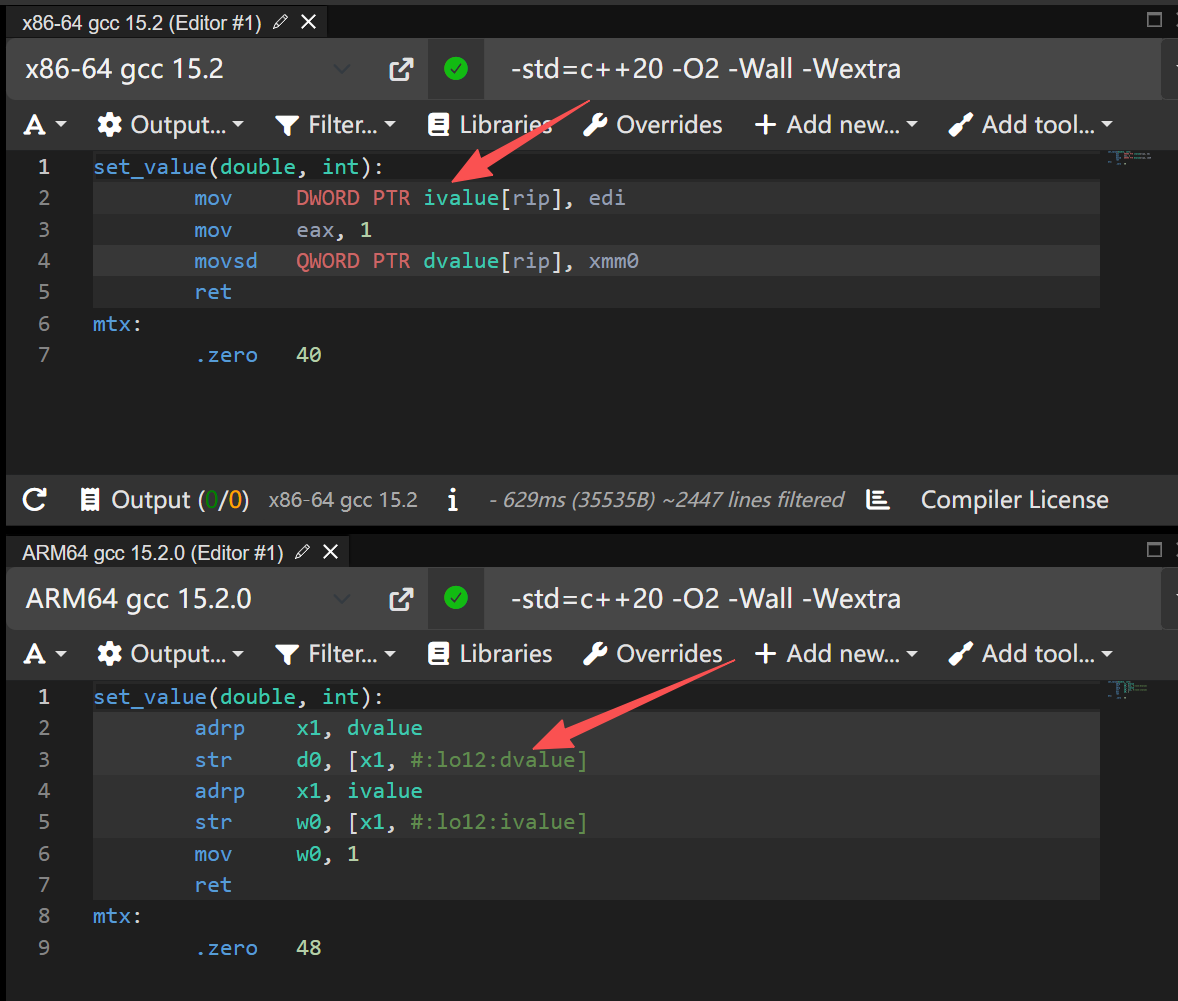
两种编译器出来的修改顺序不同,导致CPU执行的顺序也不同。加上内存屏障:
1 |
|
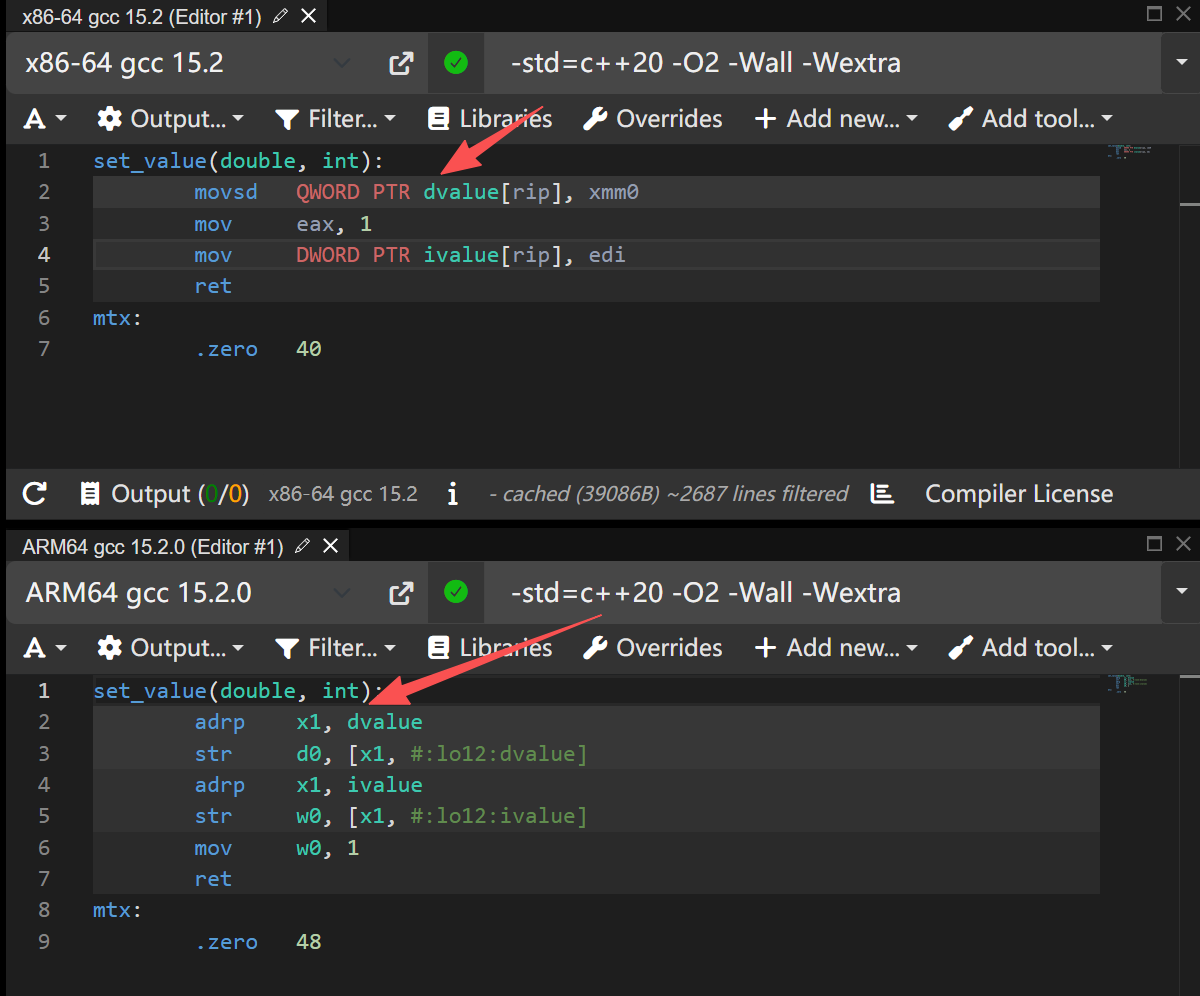
加上内存屏障编译之后,发现修改的顺序被更正为一样的了。
我们使用上面memory_order_relaxed的实验代码加上栅栏:
1 | std::atomic<bool> x, y; |
我们在1处加入了释放栅栏,在2处加入了获取栅栏,两个栅栏因此形成同步。这一改动让变量x的存储操作一定会在载入操作之前发生,因此断言一定不会被触发。